
自從OpenAI所開發的生成式模型(Generative Pre-trained Transformer)爆紅之後,
關於於其訓練資料來源(網路、書籍與公開文本)正當性的質疑便從未停止過,
或許是為了回應大眾對於隱私與智慧財產權的憂慮,
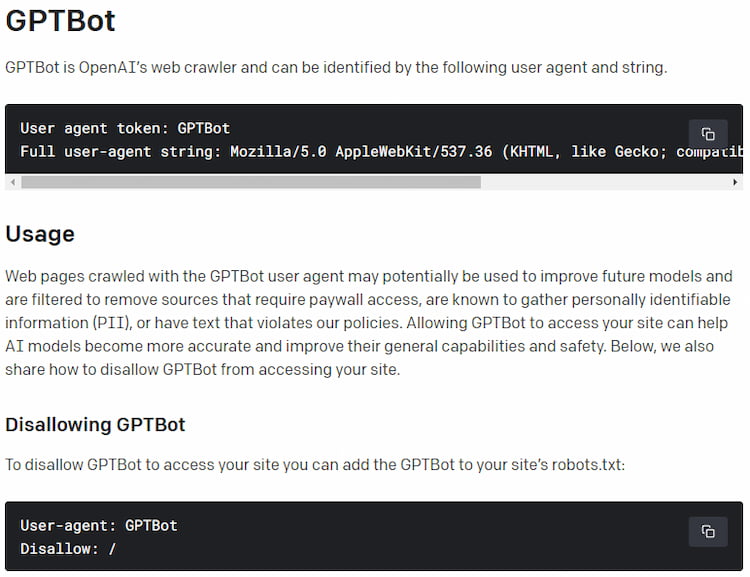
OpenAI總算在日前釋出了其網頁爬蟲”GPTBot”的相關細節;
若打算拒絕提供任何資訊或控制可給OpenAI使用之內容範圍的話,
可別忘記趕緊修改自己網站的robots.txt囉!
ChatGPT開發商OpenAI公開其網頁爬蟲「GPTBot」相關資訊
標籤: AI, robots.txt, SEO, 網路