
自從OpenAI所開發的生成式模型(Generative Pre-trained Transformer)爆紅之後,
關於於其訓練資料來源(網路、書籍與公開文本)正當性的質疑便從未停止過,
或許是為了回應大眾對於隱私與智慧財產權的憂慮,
OpenAI總算在日前釋出了其網頁爬蟲”GPTBot”的相關細節;
若打算拒絕提供任何資訊或控制可給OpenAI使用之內容範圍的話,
可別忘記趕緊修改自己網站的robots.txt囉!
(以下內容引述自iThome)
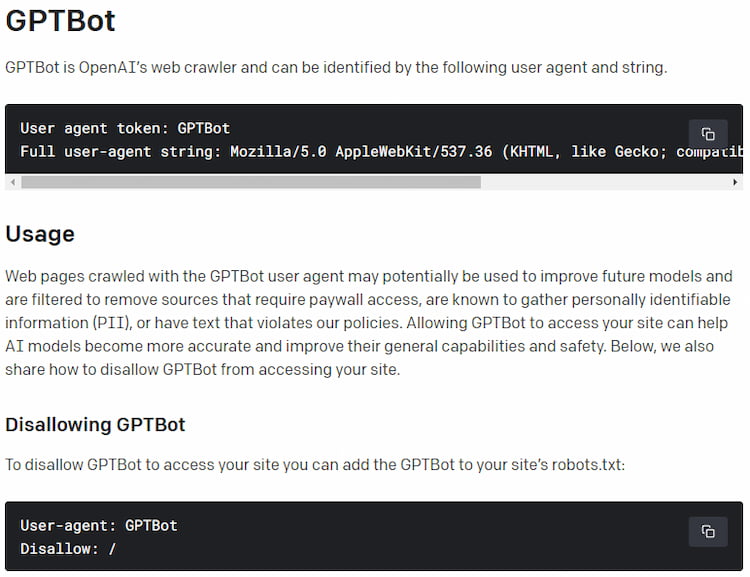
…..OpenAI表示,以GPTBot user agent抓取的網頁資料可能會用於改良未來模型,
過程中會篩選掉需要付費的來源,但其中仍可能包含可辨識身份的資訊,
或是違反OpenAI政策的文字…..
…..若網站管理員允許GPTBot存取網站,將可協助改進AI模型的精確度,提升其能力及安全。
但若網站管理員不希望其網站被蒐集資料,OpenAI也提供了拒絕的方法說明。
包括在網站robots.txt檔案中加入GPTBot(如圖),也可以自訂GPTBot存取網站部份內容(如圖)。
此外,OpenAI也公布GPTBot使用(https://openai.com/gptbot-ranges.txt)的IP位址範圍,方便網站辨識與封鎖…..
…..此類透明化措施可說是OpenAI對媒體或內容網站對AI模型業者未經同意蒐集資料的批評的回應。
現在普遍認為,業者未經同意蒐集公開網站的內容來訓練自己的AI模型,侵犯了智財權、隱私權;
他們應該要提供opt-in或opt-out選項,讓網站或資料持有人決定是不是要提供自己網站上的內容…..
…..
嗯,個人對網站內容被他人使用這點算是能夠接受的,從我沒有鎖右鍵什麼的應該就能看出,
(當然,若引述本站資料後有付上出處,我看到會更開心就是了)
不過我接著應該還是會把GPTBot給加入拒絕名單,
畢竟給讀者或搜尋引擎的網頁爬蟲瀏覽或多或少有引流作用,
能夠幫助我的網站曝光,使更多人看到我寫的東西並產生交流和互動;
相反的,把資料給GPTBot也只是拿去訓練模型,對我一點好處也沒有,
被爬的時候還會增加伺服器負擔,對私人網站可說根本百害而無一利哪…..
如我這麼想的人應該很多,OpenAI不曉得會否做出什麼因應措施?
例如說將被爬過的資料索引後弄個OpenAI Search之類搜尋引擎、
供人直接檢索比對AI回應的正確性的話,應該就會有很多人(包括我)迫不急待地想加入了 XD