
從Gigazine看到的報導,NVIDIA日前於自家的GTC 2019(GPU Technology Conference 2019)中,
展示了一款以法國印象派畫家高更(Paul Gauguin)為名的深度學習應用工具”GauGAN”,
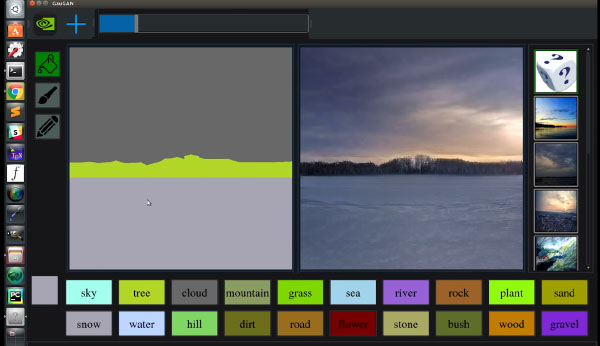
根據NVIDIA官方介紹,該軟體使用生成對抗網路(generative adversarial networks, gan)為基底,
只要從中選擇畫筆、大致描繪出背景輪廓,”GauGAN”就會依循它那受超過百萬張圖片訓練所形成的模型,
自動將圖片轉換、生成為寫實的風景圖片─”看!很簡單吧!”
(以下內容引述自NVIDIA官方部落格)
…..
…..GauGAN allows users to draw their own segmentation maps and manipulate the scene,
labeling each segment with labels like sand, sky, sea or snow…..
…..Trained on a million images, the deep learning model then fills in the landscape with show-stopping results:
Draw in a pond, and nearby elements like trees and rocks will appear as reflections in the water.
Swap a segment label from “grass” to “snow” and the entire image changes to a winter scene,
with a formerly leafy tree turning barren…..
…..“It’s like a coloring book picture that describes where a tree is, where the sun is, where the sky is,
” Catanzaro said. “And then the neural network is able to fill in all of the detail and texture,
and the reflections, shadows and colors, based on what it has learned about real images.”…..
…..Despite lacking an understanding of the physical world,
GANs can produce convincing results because of their structure as a cooperating pair of networks: a generator and a discriminator.
The generator creates images that it presents to the discriminator.
Trained on real images, the discriminator coaches the generator with pixel-by-pixel
feedback on how to improve the realism of its synthetic images…..
…..After training on real images, the discriminator knows that real ponds and lakes contain reflections —
so the generator learns to create a convincing imitation…..
…..The tool also allows users to add a style filter,
changing a generated image to adapt the style of a particular painter,
or change a daytime scene to sunset…..
…..
影片中比較不明顯,然而這個”GauGAN”真的是超乎我預期的精密,
根據前面官方的介紹,該軟體甚至還會顧及水中的景物倒影,
甚至將草地轉換成雪地後,樹木狀態也會隨著對應季節而更替;
模型會反映出訓練素材的狀態、也就是”雪地→枯木”是理所當然的結果,
但連這種細節都能反映到,並回饋到展示工具中,實在令人驚艷呢! ww
唉,這工具真是推出得太晚了些…..幾年前還比較有空摸3D、製作靜幀時,
個人大多使用VUE來製作自然背景,然而我只碰靜幀、不做動畫,
每次都要弄個明明以後幾乎不會用到的模型來渲染實在浪費時間和資源,
要是有”GauGAN”,這種工作隨便撇幾筆就能完成了啊啊…..
若能讓使用者自己訓練模型,可能連做靜幀的功夫都省了,直接出圖 XD
原研究論文: Semantic Image Synthesis with Spatially-Adaptive Normalization